平时在做数据分析的时候,会要对特征进行相关性分析,分析某些特征之间是否存在相关性。本文将通过一个实例来对数据进行相关性分析与展示。
一、数据集介绍
本次分析的是企业合作研发模式效果分析,企业的合作研发大致分为 企企合作、企学合作、企研合作、企学研合作,也就是企业与企业合作研发、企业与大学合作研发、企业与研究所合作研法、企业联合学校、研究所共同合作研发。现在就是想通过数据分析来看看那种合作研发模式的效果最好,产出最佳。
数据集是从公开网站获取的公开的专利信息,包括专利的公告日期、专利评分、专利估值,这些指标说明了专利的价值。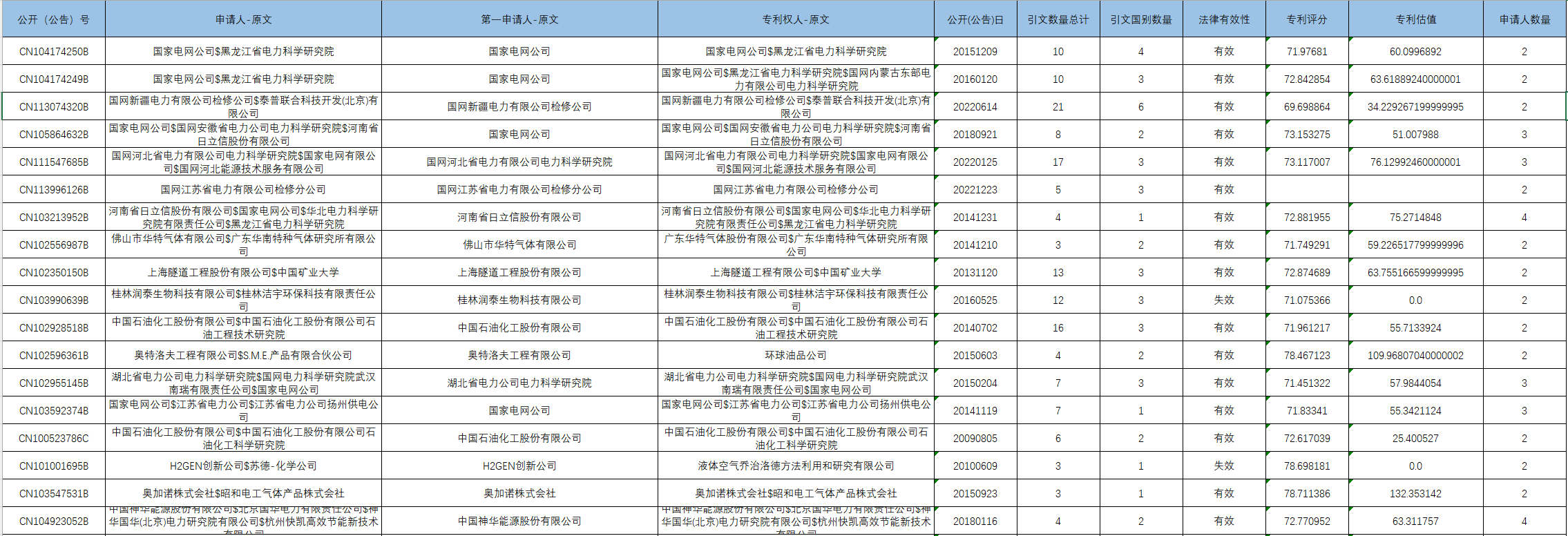
二、数据整理和探索
有了数据后先对数据进行整理,在这里我们用II表示企企合作、IU表示企学合作、IR表示企研合作、IUR表示企学研合作。
先导入python数据分析三大件numpy、pandas、matplotlib
1 | import numpy as np |
对数据进行整理,将“有效”的数据检索出来,将合作研发的模式标识出来
1 | II_data_original=pd.read_excel(r'./data/绿色低碳专利企企合作申报总数据_21578_2023-03-11.xlsx') #企企合作 |

对日期进行处理,我们以年度为单位来分析每年各企业合作研发模式的数据,所以将日期处理成“年”为单位。
1 | #处理日期 |

我们只需要分析相应的专利质量的指标,这里与专利质量相关的指标大致为引文数量、专利估值、专利评分。然后以年度为单位来看看数据。
1 | data_group=data_original.groupby(['year','class_type']).size() |
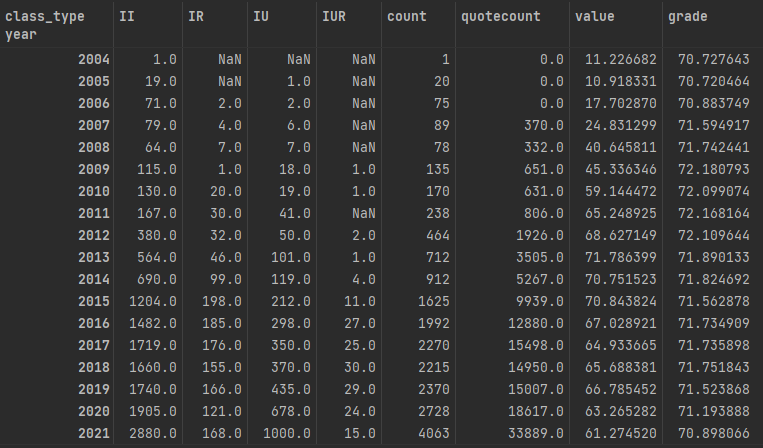
历年(2004-2022年)专利的合作模式的专利数量增长趋势
1 | df_data_group.plot.bar(y=['II','IR','IU','IUR'],figsize=(32,4),stacked=True) |

历年(2015-2022年)的合作模式的专利数量对比情况
1 | df_data_group['2015':'2022'].plot.bar(y=['II', 'IR', 'IU', 'IUR'], figsize=(32, 4)) |

从数据上可以看出,从2004年-2021年前些年,企业的研发模式是比较单一的,2004-2008年大部分都是企企合作的研发模式,其他研发模式先对比较少。从2004年-2021年,随着我国企业对研发的投入力度也来越大,专利的数量是逐年递增的,研发模式也逐步的多样化起来,但还是以企企合作和企学合作为主。
三、数据相关性分析与展示
因为从数据上看,从2015年以后各种研发模式逐步的多样化起来,所以我们来看一下2015年以后研发模式与研发质量各项指标的相关性。
通过numpyde的corrcoef()方法可以很方便的计算出各个特征之间的相关性系数,得出相关性矩阵。
1 | ruslut=np.corrcoef(df_data_group['2015':'2022'],rowvar=False) |
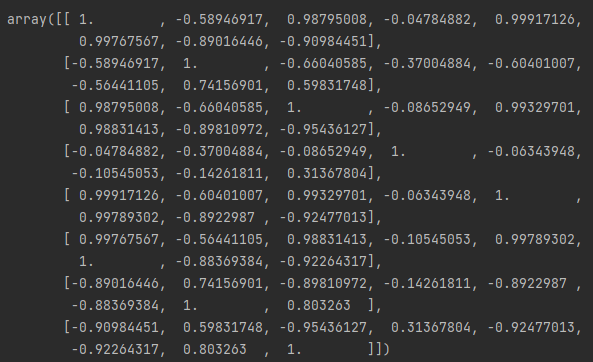
看数据肯定没有看图形直观,所以我们将这个相关性矩阵进行可视化的展示。这里用seaborn来做数据的图形化展示。
1 | import seaborn as sns |
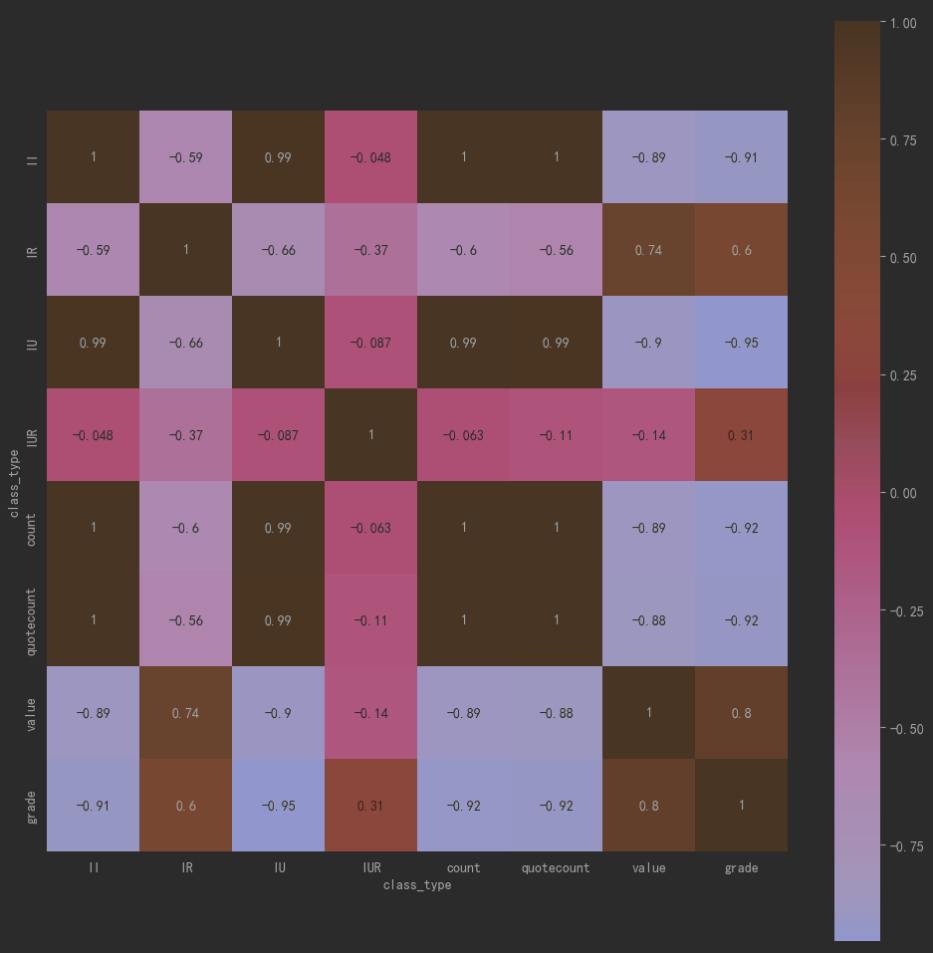
这里可以看出企企合作和企学合作的数量相关性比较高,而企研合作value和grade具有相关性,说明企研合作模式的研发质量相对来说比较好。
最后,我们来看一下专利TOP20的单位研发类型分布、估值TOP20的专利的研发类型分布、评分TOP20的专利、研发类型的分布。
1 | data_countbyComp=data_original[['第一申请人-原文','class_type']].groupby(['第一申请人-原文']).size() |
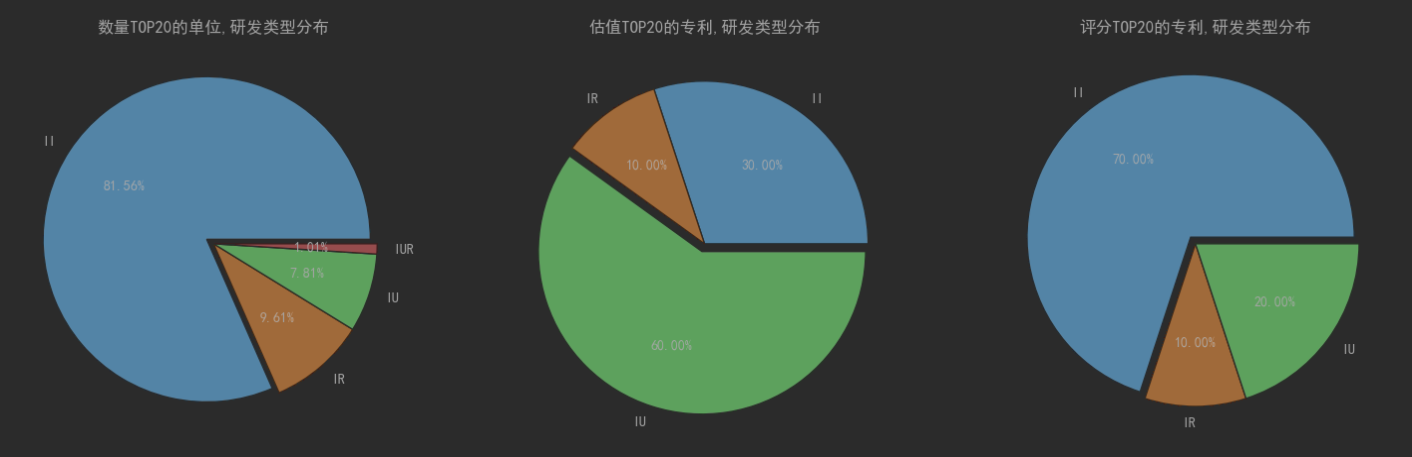
这里可以看出数量上还是以企企合作研发的模式最多,但是从专利的估值评分来看企学的专利估值占比最高。说明从 企企合作、企学合作、企研合作、企学研合作的这些企业合作研发模式看,企企合作研发数量最多,企学合作研发的质量相对较高。
至此,本文通过一个实例介绍了用python通过数据分析三件套numpy、pandas、matplotlib进行数据相关性分析的过程。
作者博客:http://xiejava.ishareread.com/

关注微信公众号,一起学习、成长!