现在很多网站要获取数据都得要先登录。Selenium是一个用于Web应用程序测试的自动化工具。它直接运行在浏览器中,模拟真实用户的操作。本文介绍如何通过Selenium来登录淘宝并自动爬取商品信息。
关于Selenium的安装与配置请参考博文《Selenium安装与配置》
一、通过Selenium模拟登录淘宝
现在要获取淘宝的商品信息需要先登录淘宝。我们先来分析淘宝的登录页面。
1、分析淘宝登录页面
淘宝登录页面为https://login.taobao.com/member/login.jhtml,支持扫描登录和用户名、密码验证登录。我们模拟用户名、密码登录。
通过Chrome浏览器输入淘宝登录页面链接F12打开开发者工具,分析淘宝登录页的源代码,找到登录账号、登录密码和登录按钮的相关控件的源代码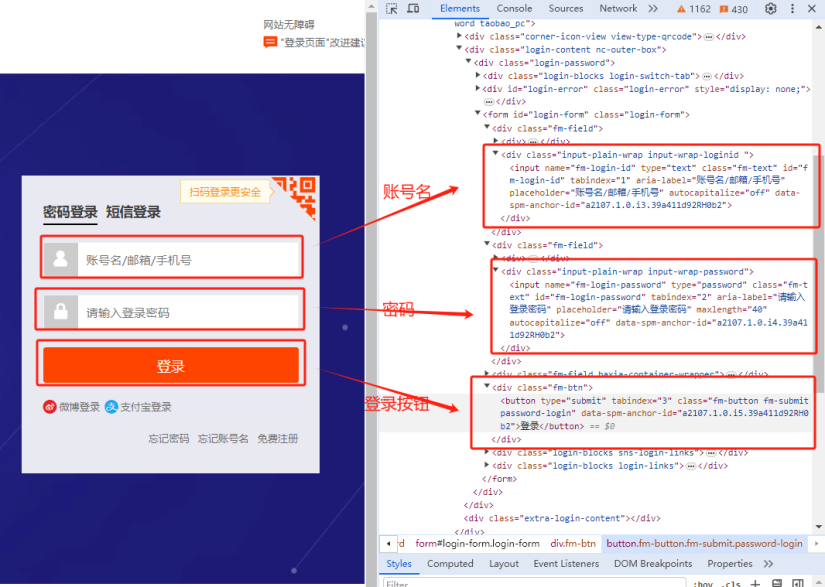
在这里可以看到
账号名的输入框控件代码:<input name="fm-login-id" type="text" class="fm-text" id="fm-login-id" tabindex="1" aria-label="账号名/邮箱/手机号" placeholder="账号名/邮箱/手机号" autocapitalize="off" data-spm-anchor-id="a2107.1.0.i1.3e3e11d9pGQKXf">
登录密码的输入框控件代码:<input name="fm-login-password" type="password" class="fm-text" id="fm-login-password" tabindex="2" aria-label="请输入登录密码" placeholder="请输入登录密码" maxlength="40" autocapitalize="off" data-spm-anchor-id="a2107.1.0.i2.3e3e11d9pGQKXf">
登录按钮的控件代码:<button type="submit" tabindex="3" class="fm-button fm-submit password-login" data-spm-anchor-id="a2107.1.0.i3.3e3e11d9pGQKXf">登录</button>
找到登录需要用的的这几个关键控件代码都就可以开始编码来控制这些控件进行模拟操作了。
2、通过Selenium实现模拟登录代码
具体代码如下:
1 | from selenium.webdriver import Chrome |
运行代码后可以看到程序自动的调起了一个Chrome浏览器并访问了淘宝的登录页面,自动的输入了用户淘宝账号和密码,自动的点击了登录按钮,但出现了一个滑动验证的控件,要求滑动验证。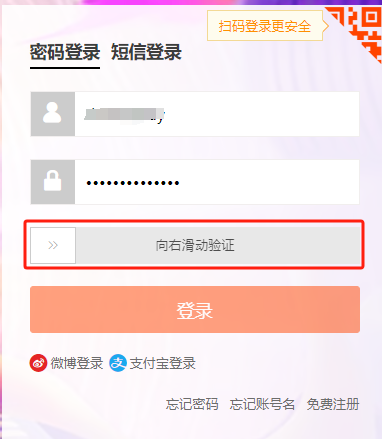
人工拖动滑动验证控件,显示验证失败。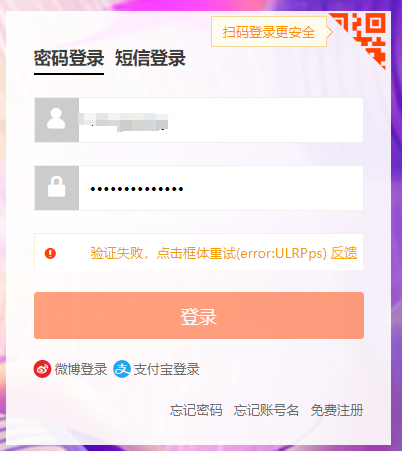
这是因为淘宝有一套反爬机制识别是否是机器自动在登录。如果是人工打开浏览器,手工输入账号密码登录就不会弹出滑动验证控件进行验证。在网上有很多办法,如可以通过代理修改chormdriver的识别码,这里介绍通过Selenium如何接管已经运行的Chrome浏览器来实现规避淘宝的验证。
3、Selenium接管已经运行的Chrome浏览器
1)启动Chrome的远程调试模式
通过chrome.exe --remote-debugging-port=9222 --user-data-dir='某个存在的文件夹地址' 启动Chrome的远程调试模式,启动一个Chrome浏览器。
找到chrome的安装目录,找到chrome.exe ,通过cmd命令行执行上面的命令。
运行上面命令后,就会弹出一个chrome浏览器,这个浏览器是可以被Selenium来接管操作的。
2)代码中实现接管已经运行的Chrome浏览器
1 | from selenium.webdriver import Chrome |
4、运行效果
运行上述代码就可以看到,Selenium接管了这个通过Chrome的远程调试模式启动的浏览器,并自动输入用户名和密码,自动登录成功,跳转到我的淘宝界面。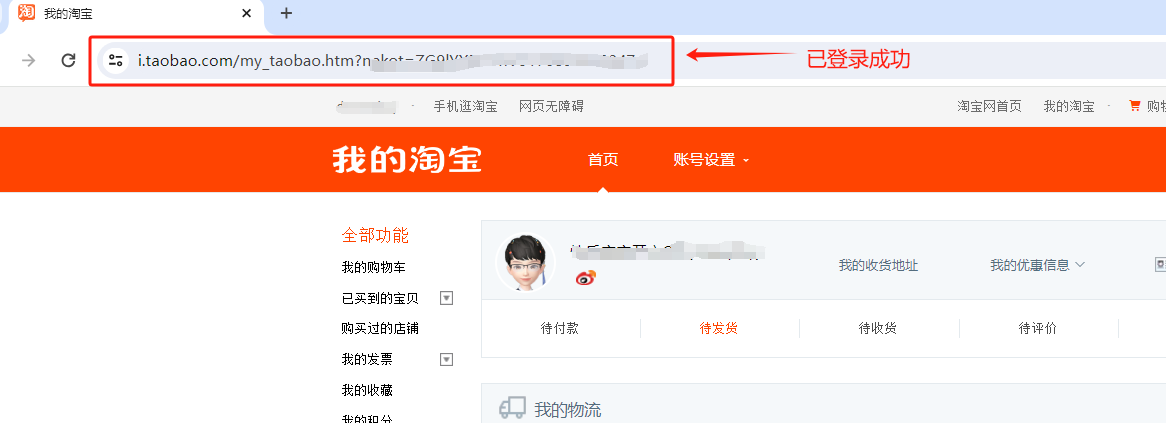
二、通过Selenium自动爬取淘宝商品信息
1、分析商品页面
https://s.taobao.com/search?page=1&q=ipad&tab=all
通过Chrome浏览器输入淘宝搜索商品页面链接F12打开开发者工具,分析淘宝搜索商品列表页的源代码,找到商品展示相关源代码包括商品的title、价格、详情页、购买情况等。我们需要通过解析这些源代码获取相应的商品信息。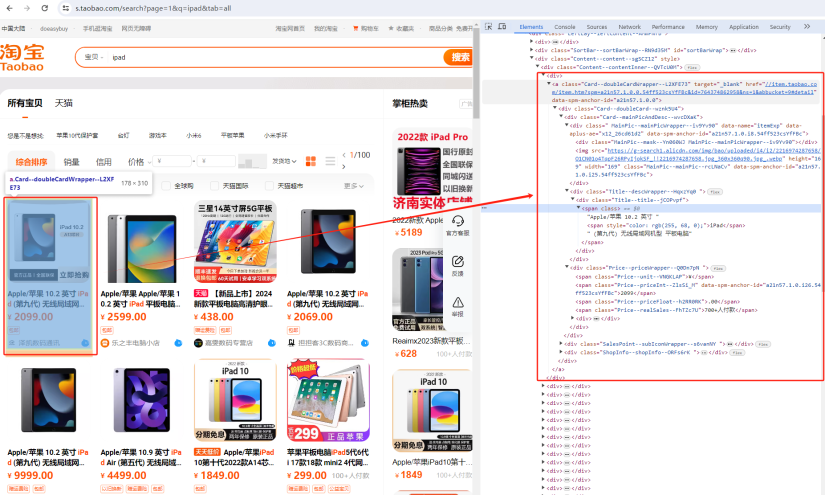
找到下一页翻页的按钮,我们需要控制下一页翻页的按钮来实现自动翻页。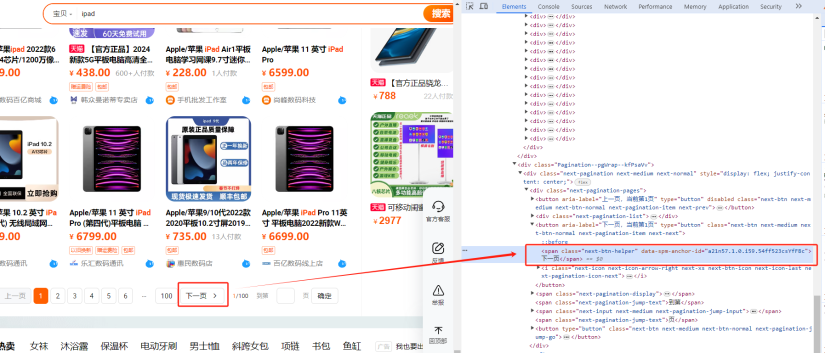
2、实现商品获取代码
1 | # 解析获取商品信息 |
3、实现效果
从浏览器看,Selenium自动访问淘宝登录页,当切到用户名密码登录界面时,Selenium自动输入用户名、密码点击登录。登录成功后,自动访问商品搜索页搜索ipad,进行商信息获取,自动翻下一页。
从后台打印的日志看,显示“开始登录”、“已经登录”,正在爬取的链接和该链接下的商品信息。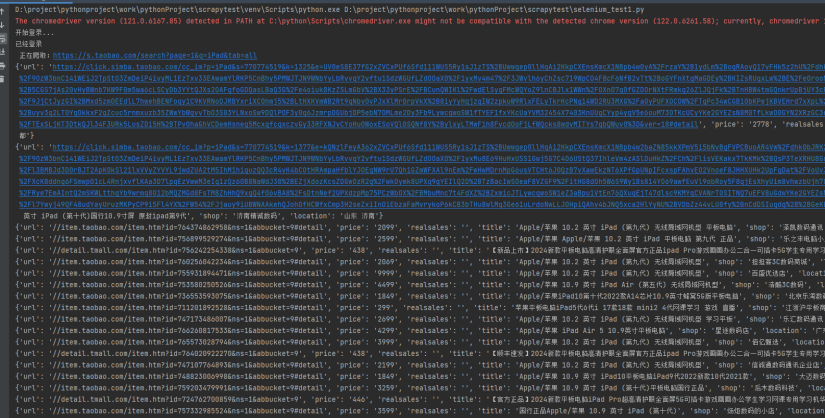
至此,通过Selenium来代码实现模拟登录淘宝并自动爬取商品信息,进行了Selenium的实战。
要注意的是:
1、在Selenium打开登录页面后淘宝默认的是扫码登录,需要人为接入切换用户密码模式。这时也可以让Selenium自动去切到用户密码模式登录。代码如下:
change_type=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ‘.iconfont.icon-password’)))
change_type.click() #切换到用户密码模式登录
2、在运行启动Chrome的远程调试模式,启动Chrome浏览器后,要关闭其他的Chrome浏览器,保留远程调试模式启动的浏览器就好了。如果是存在多个Chrome浏览器Selenium会不知道要接管哪一个。
附上全部完整代码:
1 | from selenium.webdriver import Chrome |
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!